
The Context Window Dillema
Emerging techniques for expanded context windows & their pitfalls


Talk to anyone building an LLM-application and context window limits are going to come up as one of the biggest challenges they deal with - e.g. see these blogs by HoneyComb and Earthly.
While context window sizes have increased dramatically over the past few years - with newer models like Claude2 now offering 100k context windows - for many use cases this is still many orders of magnitude too small.
What might lead to step function improvements in context window size, and what are the challenges and issues associated with larger context windows? This essay highlights a number of recent research papers that explore these questions, discusses the broader role of context windows in LLMs over time, and touches on reasons why large context windows may not be inherently better for teams building with LLMs.
The basics - what constrains context windows size?
The driving factor that constrains context window size is that self-attention, the eponymous (“Attention is All You Need”) mechanism by which transformers determine what words relate to each other when generating output, scales quadratically with input length.
The reason for this is that, for each new word a transformer generates in a sequence, it computes weights for all prior words in the sequence thus far, which is an O(N^2) computation. This is part of what allows transformers to be so effective - attention effectively models complex long range interactions between tokens - but it comes at a cost. Things that scale quadratically get very expensive very fast: a context window 8x the size would cost roughly 64x as much to train. As such, the context window limit ultimately bakes down to a computational problem.
There is a related issue that training larger context window models also requires finding appropriate datasets. If you want to train a model with a 1M token context window, you need to find enough training data examples with 1M tokens in it that include true long range dependencies. This gets exponentially harder at larger sizes - e.g. many books are <100k tokens.
For awhile, various papers have explored ways to reduce the computational burden of attention and therefore improve context windows and sequence lengths - e.g. see this paper on sparse attention from 2020. However, recently there has been a particular influx of new papers in this domain. So, let’s explore them.
Emerging Methods for Larger Contexts
Hyena Operators
Hyena is a paper that explores an alternative mechanism to attention they call “Hyena Operators”. The researchers did some empirical testing with “synthetic languages” - essentially, made up languages that make it easier to identify what architectural primitives drive performance for different tasks - to ultimately identify 3 traits that they believe are the core drivers of the performance of attention.

The three traits they identify are as follows (I am somewhat simplifying):
Data Control: The operator must define its linear operations as a function of the input data.
e.g. Self-attention can be expressed as y = A(k, q) * v where A is the attention matrix conditioned by linear projections k, q of the input
Sublinear parameter scaling: The parameter count of the operator has to be decoupled from the sequence length it is able to look at.
e.g. an anti-example would be FIR filters, which must scale parameters linearly with the filter size they look at
Unrestricted context: The operator has to be able to analyze arbitrarily long-range dependencies between any two parts of an input
The key insight of the paper is identifying a novel operator built out of a recurrence of 1. A very particular type of convolution - implicit, long convolutions - and 2. Element-wise multiplicative gates. Both of these primitives scale sub-quadratically, and in combination they meet all the traits specified above. Therefore, in theory, this operator should convey similar performance to attention, while scaling much more optimally.
Notably, while there has been various past work in sub-quadratic attention alternatives, this is the first paper that has really demonstrated similar quality as transformers. They reach GPT quality for basic language modeling tasks on The Pile dataset with a 20% reduction in training compute; they show Hyena operators being twice as twice as fast as highly optimized attention at sequence length 8K and 100x faster at sequence length 64K; and they demonstrate strong performance lift with in-context learning, a characteristic behavior of transformers.
Perhaps the most interesting datapoint for Hyena operators, however, is the team’s recent followup paper: HyenaDNA. This paper applied the Hyena operator methodology to building a genomic foundation model, which is in many respects a perfect illustration of what a sub-quadratic attention-like operator allows.
As a quick recap, genomes are constructed as a sequence of nucleotides - adenine (A), cytosine (C), guanine (G) and thymine (T) - which together form DNA. In theory, a large genomic model pre-trained auto-regressively (e.g. given a sequence of nucleotides, predict which nucleotides come next) would enable a number of interesting genomics use cases, such as genomic classification or assist in devising gene therapies.
However, thus far, there have been essentially no notable genomics models of this form, because genomics suffers from a few key issues tied to context window limits:
Genomic sequences are huge - billions of nucleotides. This is hard to make work when major LLMs support at max ~100k token context windows right now.
Genomic sequences have long ranging dependencies/interactions - a nucleotide sequence at position X might impact something else millions of nucleotides away. As such, it's critical the context window supports capturing these long range dependencies.
It is very important to capture raw nucleotides as inputs, rather than tokenizing the input into higher level structures (a way to de-facto "increase" context window), because single nucleotide variants can have dramatic impacts
The paper ultimately shows that Hyena operators allow them to train a genomic FM with context lengths up to 1 million tokens at single nucleotide resolution, a 500x increase of existing genomic FMs using dense attention. They then demonstrate that this model is clearly state of the art for a wide range of downstream genomic tasks - such as promoter classification - via fine tuning.
State Space Models
The Hungry Hungry Hippos paper referenced by Hyena itself introduced an alternative to transformers: State Space Models.
State space models (SSM) are a longstanding mathematical approach to modeling which essentially models a system where you assume that an input signal u(t) maps to an output y(t) via some intermediate/latent state x(t), subject to the following system of equations, where A, B, C, and D are some learned matrices:
x'(t) = A*x(t) + B*u(t)
y(t) = C*x(t) + D*u(t)Notably, SSMs scale linearly with sequence length. In the paper, they develop a novel SSM layer which they call H3 that matches attention on various synthetic language tasks, and they then train a hybrid SSM + attention model which outperforms Transformers on some benchmarks. The paper also explores how the lack of native hardware support for SSMs may actually be artificially limiting their efficacy vs. transformers & attention.
Various other research work has been done in this space, such as this paper.
MegaByte
Megabyte is a recent paper out of FAIR that introduces a different approach to dealing with the quadratic scaling of attention (in addition to dealing with the issues associated with tokenization).
The basic idea is that you make the attention layer hierarchical, combining local small models which operate on a “patch” level with global large models which operate across all "patches”. Intuitively, the reason this is theoretically more efficient is that the patch-level prediction tasks that the local models handle are in theory quite simple, meaning a small model can perform just as well as a large model. By shifting a large percentage of the work to small models, you should therefore get a computational reduction while maintaining performance.
Crucially, we observe that for many tasks, most byte predictions are relatively easy (for example, completing a word given the first few characters), meaning that large networks per-byte are unnecessary, and a much smaller model can be used for intra-patch modelling.

The paper demonstrates compelling performance on a range of tasks that involve extremely long sequences, such as audio processing. You could imagine extensions of this research that explore further variations of this concept - e.g. what if there were three or four layers of models that all interacted at different dimensions, from words to sentences to paragraphs to higher order concepts? LAIT explores some similar ideas.
Mega
Mega explores combining attention with an exponential moving average (“EMA”) filter as a way to reduce the computational scaling of attention.
Attention does not assume prior knowledge of the patterns of dependencies between tokens (“positional inductive bias”), but rather learns all pairwise attention weights directly from data. EMA filters, in contrast, structurally assume that pairwise relationships between tokens drop off exponentially with distance/time.
As a simple analogy - attention would assume that within a book, any paragraph could relate to any other paragraph with almost equal probability, and so you just need to learn the relationships from the data. EMA would assume that within a book, paragraphs within the same chapter are more likely to relate to each other than paragraphs across chapters. EMA essentially makes a prior assumption about the relationships between data, and as a result is more computationally efficient since it does not need to “learn” such a relationship.
The basic intuition behind the approach in the Mega paper is that, if you believe that most relationships between tokens follow this exponential decay relationship, then you benefit from not relying entirely on attention, but instead using the more computationally efficient EMA filter.
The paper specifically introduces an attention mechanism they call a moving average equipped gated attention mechanism (MEGA) which incorporates the positional inductive bias of EMAs. The paper demonstrates that this mechanism has interesting performance advantages particularly on various long sequence tasks such as those in the Long Range Arena.
LongNet
LongNet is a recent paper that introduces a concept they call “dilated attention”, which allocates exponentially decreasing attention between pairwise tokens as their distance grows. They argue that this mechanism can allow for sequence lengths of 1B tokens.

While the paper does not actually train a model anywhere near 1B tokens - the 1B value comes from them measuring the average speed of forward propagation for different context lengths and showing it scales essentially linearly with sequence length - the research is nonetheless interesting. The dilated attention algorithm also allows for a novel distribution algorithm to be used in training,
Philosophically, this is extremely similar to what the researchers did in the Mega paper - in each case, you alter attention to focus more on more proximate data with some learned exponential decay function.
RMT
RMT is a paper that shows that, by modifying transformers to have a recurrent memory layer, you can dramatically scale sequence length to up to 1M tokens thanks to improved computational efficiency. This paper outlines the details of the memory layer in substantially more detail.
The basic concept is that instead of having one massive set of pairwise computations across the sequence as is common with attention (see left image below), you split the sequence up into a series of recurrent segments, and you simply pass a memory block between segments. Because Segment N+1 only interacts with the memory block of Segment N, rather than interacting with the individual elements in Segment N, you dramatically lower the computational complexity.

The memory block is quite analogous to the “cell state” that is passed in recurrent neural networks.
The paper shows that this approach leads to strong memory retrieval accuracy up to ~2M tokens, with the paper testing a range of memory & retrieval tasks related to large context window sizes (e.g. put two facts randomly in a large context window filled with other information, and then ask a question which requires combining those two facts)

Monarch Mixer
(Added July 25 after initial publication of this post)
Monarch Mixer is another recent paper out of Stanford and Together.xyz which proposes a different sub-quadratic attention alternative based on Monarch Matrices.
Monarch Matrices are a specific type of structured matrix which can be expressed as the product of two block diagonal matrices that are interleaved with permutations. Below is the more formal definition from the original paper, as well as a diagram illustrating the concept.


There are two key interesting aspects of this specific class of matrix. First, it is computationally expressive in the sense that it generalizes the fast fourier transform function. This is important because, as we have seen with Hyena, long convolutions are becoming an increasingly popular alternative to attention, and FFTs can be used to compute long convolutions.
Second, these matrices are very computationally efficient. The Monarch Matrix design allows it to take advantage of modern hardware (solving one of the problems you saw with state space machines), and it scales sub-quadratically at O(N^3/2).
This combination of properties allows it to be used to replace two key components of Transformers - the attention mechanism and the feedforward MLP block - in a way that should allow such models to theoretically scale much more effectively.
In Monarch Mixer (M2), we use layers built up from Monarch matrices to do both mixing across the sequence (what attention does in Transformers) and mixing across the model dimension (what the MLP does in Transformers). This is similar in spirit to great work like MLP Mixer and ConvMixer, which similarly replaced everything with a single primitive for vision tasks (but went for quadratic primitives).
The work goes on to experimentally demonstrate doing this for the BERT model. The resulting Monarch Matrix based BERT achieves similar quality scores to BERT on various benchmarks with fewer parameters. It also demonstrates substantially higher throughput for long sequence lengths, a direct representation of the better scaling properties of the Monarch Matrices.

Summing Up
Summing these papers up - we can observe a few common patterns.
First, many papers revisit some of the traditional techniques seen in older deep learning architectures such as RNNs and CNNs. Hyena uses a convolutional operator, RMT adds a recurrent memory unit, and M2 is ultimately based on long convolutions via the monarch matrix.
Second, many papers explore ways of slightly modifying attention under the assumption that full multi-headed self-attention is perhaps overkill in various cases. Megabyte uses hierarchical layers rather than one global attention layer, LongNet uses dilated attention, and Hungry Hungry Hippos uses a hybrid attention + state space model mechanism.
However, while a lot of this research is clearly compelling, we are still far from the point where long context is solved. To explore this in more depth, let’s discuss another recent paper.
The False Promise of Larger Contexts
Lost in the Middle is a very interesting recent paper that explored the performance characteristics of models with large context windows. They make two key observations:
The ability for a model to effectively retrieve and/or utilize information in its context varies dramatically based on where the information is in the context window. Specifically, information at the start or end of the context window is much more retrievable than information in the middle.
Overall, the performance of many models, including explicitly long-context models,. substantially decreases as the input context grows
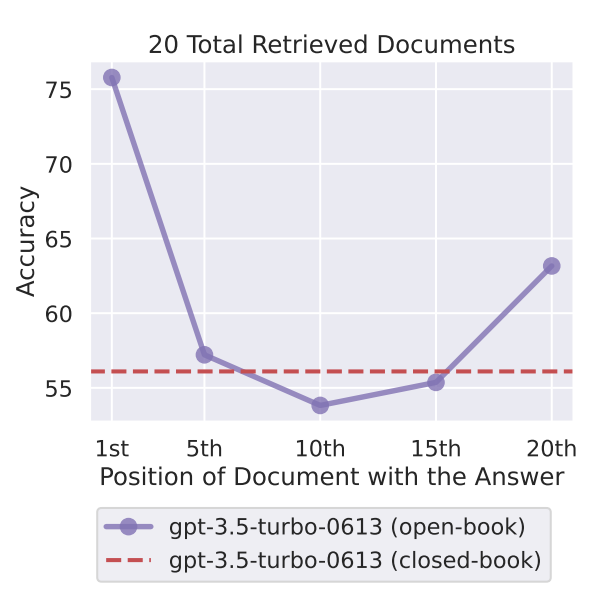
The broader implication of these two observations is that longer context windows may not actually be as valuable as they are perceived to be, at least right now; even if you have a large window, the model may not be able to use it effectively.
This also highlights how critical it is for papers on long context windows to not only evaluate performance characteristics, but also accuracy metrics. It is very difficult to predict how well a model will be able to “utilize” a long context window, as well as to understand how “softening” the attention algorithm will impact reasoning capabilities for different tasks. One of the reasons I specifically like the Hyena paper is due to how they rigorously analyze the specific architectural traits that lead attention to perform well, and ensure they maintain them with their new mechanism.
Below is an image from Harrison Kinsley that analyzed Dilated Attention in the lens of the Lost in the Middle paper - note how accuracy goes down dramatically even at the 1M context length, despite the model being espoused to support 1B token sequence lengths.

The Interplay Between Retrieval & Context
“Even if a language model can take in 16K tokens, is it actually beneficial to provide 16K tokens of context?” This question is posed near the end of the Lost in the Middle paper, and it is worth considering in more depth.
Today, anyone building an LLM-based application basically has two choices for determining what data is relevant for the model at inference time. Either you explicitly identify relevant information with a retrieval & ranking system, or you implicitly select which data is relevant by just feeding as much as possible into the context window and hoping the model figures it out.
The latter is obviously much simpler, and it is a big reason why so many teams are desperate for larger context windows. Yet, as we have seen, we are clearly far from an ideal world where the models can handle arbitrarily long context, and there are likely always going to be foundational tradeoffs between larger context windows and increased latency, cost, and accuracy.
From speaking with many people who have built LLM-applications, there is immense value in “context curation” - very carefully analyzing what data, when fed into the context window, actually improves performance vs. not. CoPilot benefitted a lot from extremely precise and well-crafted context building, and I see a similar pattern among many newer startups building agent-based systems or more complex LLM features. In many cases, the more you can shift to a complex retrieval and ranking system and the less you ask the model to determine what information is relevant, the better.
I suspect that the relatively small context windows of today may actually lead people to build better products in certain cases - the context window size constraint forces teams to really think about what information is most useful or relevant, and feed only that to the model. This is analogous to the longstanding understanding in the traditional machine learning world that feature engineering is far more important than modeling in most cases.
For this reason, I don’t think larger context windows are the panacea they are sometimes made out to be. A corollary of this is that traditional search and information retrieval backgrounds are massively undervalued for startups building applied LLM products.
Great teams go well beyond just doing k-nearest neighbors search with a vector database and stuffing the top N results that fit into the context window. They explore reranking (see also here), filtering, boosting, novel index structures, and hybrid search systems that combine vector search with keyword search. More generally - they build complex multi-layer retrieval pipelines. This blog by PostgresML does a good job of outlining some of these ideas in more depth, and this blog by Kailua Labs gives some example of this in the context of multimodal search.
The importance of these techniques may, ironically, only increase as context windows increase in length.
Looking forward - the role of large context windows
I do not mean to overly diminish the potential value of longer context windows. There are many domains such as genomics, biology, audio processing, and more which naturally have massive sequence lengths that will require much larger context windows to get anywhere. And clearly, the emerging research is starting to enable use cases in these areas - HyenaDNA is a clear example of something valuable that is newly possible thanks only to rethinking the attention mechanism.
The key question on my mind is - will these “long context” model architectures become the default, or will they be selectively used in the domains that truly require ultra long context. Absent some major research breakthroughs, my guess is that for the foreseeable future, while 1M+ context window models will get built, they will not necessarily be used in a general purpose way given their tradeoffs. And even if such models do become the standard, my guess is that many teams may benefit from trying to minimize how much context the actually use, rather than starting by filling as much as possible.
However - I’d be very curious if you disagree! And more broadly, let me know if I am missing any major research trends for expanding context windows or changing how attention scales computationally.
Appendix - Continuous Training, Integrated Memory & other Techniques
How will the value context windows evolve as foundation models allow for more “continuous training” paradigms? Part of the value of extremely large context windows today is to offset the fact that large FMs are only trained every 6-12 months. If it is possible to easily do incremental training on FMs with new datasets on a regular basis, the line may blur more between when it makes sense to update model weights vs. feed data into the context window (though I don’t think we will ever fully move away from information being fed to the model at inference time).
As model architectures begin to bake in retrieval more natively (e.g. see RETRO), what will the impact on retrieval systems and context windows be?
I suspect attention will continue to be optimized heavily in the coming years - e.g. see Flash Attention. This will also play a big role in expanding context window sizes.
LongMem is another interesting recent approach that handles long input sequences by inputting chunks of the sequence into the LLM one at a time, storing the attention values for that sequence in a distinct memory store, and then retrieving top-k attention key-value pairs for each future input.
ALiBi shows that you can use a different positional embedding than sinusoidal encoding, such that you can train on small contexts and then fine tune on larger contexts. MosaicML has explored doing this
This is a great blog post showing some other methodologies as well as covering some I have mentioned in more mathematical detail
“Do we Need Attention?” By Sasha Rush at Cornell
LLMs Beyond Attention by Interconnects AI