
How Agents Use Systems Differently
Why databases, distributed systems, & more will need to be re-architected for a new type of user

Increasingly, coding agents are the ones provisioning and interacting with systems such as databases, distributed systems, computing runtimes, APIs, and similar types of cloud services. This is driving a need to redesign such systems to account for the fact that agents use them quite differently than humans, and have somewhat divergent requirements.
This blog post outlines the patterns I have seen thus far that seem to be most universally beneficial and important for serving agents. Note that I am not aiming to discuss “agent experience” here - which gets more at things like how to make it easy for agents to discover, understand, and use your service (e.g. account creation via CLI, markdown based docs, everything as an API) - but rather how systems should be designed differently to serve agent workload patterns.
Snapshotting & Time Travel
Agents make a lot of mistakes, but are good at back-tracking and correcting those mistakes if there is an easy way to do so. Systems that therefore make it easy to regularly snapshot system state at a low overhead and then recover from that start are particularly amenable to agent query patterns.
Good examples of this include Replit’s snapshot engine and how every sandbox vendor is pushing hard on supporting full memory + disk snapshots (e.g. Cloudflare, Daytona). See also Tigris recent post on snapshotting.
Branching & Copy-on-Write
The ability to rapidly branch the state of a system at a low relative cost is extremely valuable for agents.
Agents benefit from high degrees of parallelism, exploring many different ideas or options simultaneously and then converging on the optimal ones. As a result, agents tend to want to branch the system state much more readily than humans typically do, and it is thus essential that techniques like copy-on-write are used to make this more efficient.
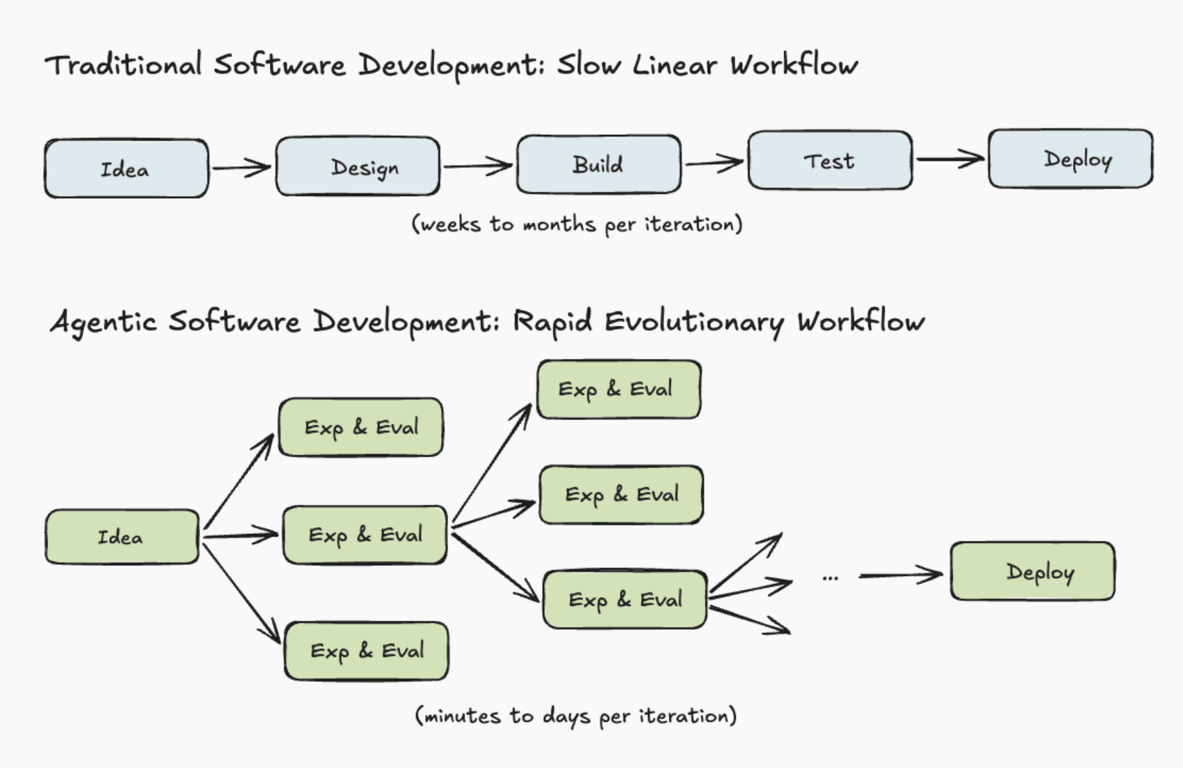
Furthermore, in such scenarios, you often want each agent’s exploration to be sandboxed such that it can not interfere with other agents, nor mess up your production state. For example, if your agent is developing a new data pipeline that hydrates a production table, you ideally want the agent to be able to fully explore and test doing that without there being any risk of corrupting the production state.
Correspondingly, I think the importance of “git-like” semantics in systems is going up a lot - because if you are branching, you also want first class resolution operations like rebasing, merging, etc.
I will note that, in spite of the large number of databases advertising efficient branching, there is still a lot of performance optimization work to be done in this space. See for example the BranchBench paper
We evaluate state of the art systems including Neon, DoltgreSQL, Tiger Data, Xata, and PostgreSQL baselines, and find a fundamental tension: systems optimized for fast branching suffer up to 5−4000× slower reads as branches deepen, while systems optimized for fast data operations incur 25−1500× higher branch creation and switching latency. Further, no current system supports the representative workloads at scale. These results highlight the need for branch native DBMSes designed specifically for agentic exploration.
Good examples of database doing this and advertising it specifically as a useful tool for agents include Neon DB Branching, Bauplan Git-for-Data, Tigris bucket forking, Databricks lakebase branching, and Ardent Postgres cloning.
Another good example of this playing out recently is how git worktrees have become enormously popular with coding agents, when they were traditionally quite niche versus simply doing branches. Worktrees are essentially a more “complete” version of branching than a git branch since they encapsulate the environment and the code.
Yet even here, there is more work to be done - see for example the following thoughts from one of the leading sandbox vendors, Daytona:
Consider coding agents running in a sandbox. Today, you have two options - you can create real branches, but they leak into the remote, or you can skip branching and lose clean merge-back. What you really want is complete branch, rebase, and merge functionality within the sandbox that doesn’t leak to the remote until you want it to. The primitive still isn’t there - Vedran, CTO of Daytona
Rapid scale up & scale down
Agent workloads tend to be very spiky - with much higher variance jumps up and down than human workloads.
As an illustrative example, consider the role of a data analyst. A human investigating something might:
Run a query
Spend a few minutes analyzing the results
Spend a few minutes updating the query or writing a new query
repeat
Each query is interleaved by a lot of human time to analyze, consider, and identify the next step - with the end-to-end workload being effectively spaced out over intervals.
An agent data analyst investigating the same thing will collapse all the above steps into a rapid series of back-to-back queries all run in a very short time span, then be done. The overall workload got condensed from maybe an hour to <1 minute.
This dramatically increases the need for infrastructure that is designed to rapidly scale up & rapidly scale down. Without this, you will either be unable to respond to agent demands, or you will be massively over provisioned and thus very cost ineffective.

Most traditional systems infrastructure - especially more stateful systems - has generally assumed some degree of always-running components and some fixed floor on operational cost. Serverless, highly elastic infrastructure has, for the most part, been more of a niche.
Agents are completely upending this. Databricks has a fantastic blog post showing how on Lakebase, thanks to agents, the median database compute time is less than 10 seconds (visual below). If you do not have a database system designed for this degree of ephemerality - likely built around concepts like stateless compute workers, no specialized coordinators & leaders, and separation of storage & compute - it is almost impossible to serve the workload economically.
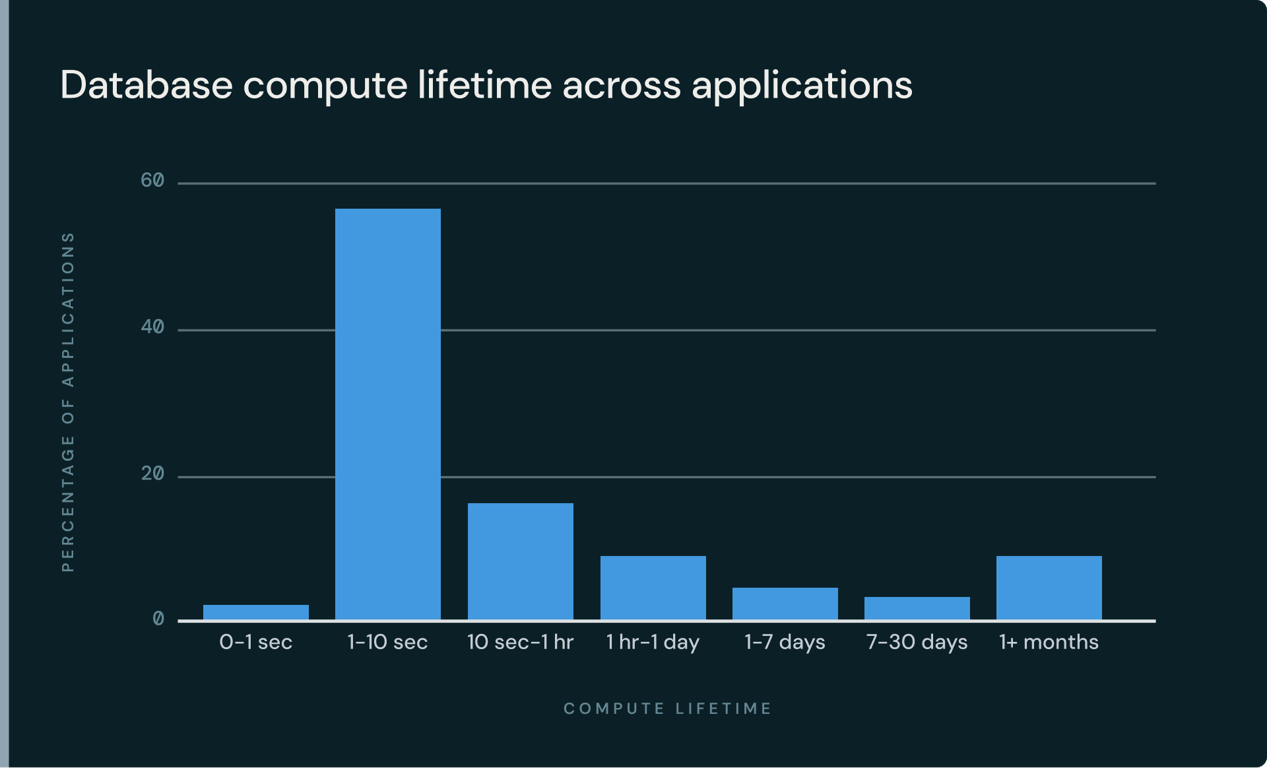
There is now research that suggests that extreme burstiness of agent query patterns can actually create more even profound problems systems. This paper by MongoDB highlights how what they call “agent spikes” - super rapid, high volume, retry heavy agent query patterns - are actually so different from human patterns that they can cause ongoing degradation or failure of a system because they get into a negative feedback loop with dynamic mechanisms like load shedding and queue management. In other words, human system design is so poorly adapted to agents that agents can simply break the system.
See also Xata’s recent OSS launch focused on the platform being designed for agents, highlighting “automatic scale-to-zero and wake-up on new connections” as a core reasons why.
High-concurrency
Agents are capable of much more parallel query patterns than humans. Web search is good example of this. If you ask Claude to do deep research on a topic, it will do 10+ web searches in parallel. This is profoundly different from how humans do web search, which looks more like a single threaded series of sequential queries.

This behavior is largely a function of the fact that agents have a much higher effective information processing bandwidth than humans. This means that systems designed for agents need to account for much higher degrees of concurrency and parallelism, particularly in the context of an individual client.
I suspect that this may substantially influence how a system caches. The more parallelism, the higher the need for, and opportunity for, intelligent re-use of work. A parallel swarm of agents trying to solve something for a given user are very likely to make semi-redundant queries that produce similar results.
For example if a bunch of agents are doing exploratory analysis on a Snowflake table, and agent 1 runs:
SELECT col1 FROM table WHERE date = JanuaryWhile agent 2 runs:
SELECT col1 FROM table WHERE date >= January and < MarchOne could essentially rewrite query 2 as:
SELECT col1 FROM table WHERE date >= February and < March
UNION
SELECT the previous query from cacheWhile this sort of semantic caching optimization could be useful for humans, its importance goes up dramatically in more concurrent query environments because it increases the likelihood of a cache hit. Thus, the concurrency present in agentic may pressure systems towards more sophisticated cache optimizations - some interesting recent examples in the OLAP space being LiquidCache and Bauplan’s differential cache (reminiscent in some ways of Noria)
Isolation & Contention Management
In many cases, systems designed for agents will need to deal with a much higher rate of contention given the dramatically higher net volume of queries & requests being made by agents in parallel.
This increases the importance of techniques that help mitigate contention and encourage isolated edits/changes. Branching is one such approach, but there are others.
For example, designing a storage layout to account for many agents wanting to make many very small edits in parallel without having to place locks on very large segments of data - an advantage Mesa’s versioned filesystem has over solutions like S3 Files.
Another example of this is conflict-resolution techniques like CRDTs. For products where a large number of humans and agents are jointly collaborating on shared state, data structures like CRDTs that allow for high degrees of parallel edits or manipulation of data may become more popular.
High volume, small data
In general, agents gravitate towards doing high volumes of “small” data work. Coding agents are creating 10000x the number of repos that existed before, but each repo tends to be much smaller on average. Data analysis agents tend to do a lot of small to medium sized analyses, but far fewer giant queries. Agents running sandboxes tend to produce a huge number of very small filesystems.
An immediate impact of this paradigm is it breaks the rate limit assumptions of a lot of existing infrastructure - e.g. companies like Lovable literally can not use Github because they exceed repo creation rate limits by multiple orders of magnitude, leading to companies like Mesa & Relace. The more subtle impact is it fundamentally changes how you want to store data and metadata.
Storage systems are designed around assumptions on the rough shape of a workload - the ratio of (number of objects) to (size per object) to (operations per object), the metadata-to-data ratio, the typical lifetime where an object is “hot”, the read-to-write ratio, etc.
If you suddenly have 1000x more cardinality, a totally different metadata to data ratio (as you need to keep track of a lot more data but each object is much smaller), and a different object lifecycle - things can utterly break. The “Small File Problem” in Hadoop is a classic, older example of this pattern.
This has a substantial impact on system design. Advanced namespace techniques like hash based addressing, prefix sharding, and other more efficient ways to traverse large name spaces become important. It becomes more critical to ensure there is not a high metadata overhead per object - e.g. large footers or headers. As the read-to-write ratio of the workload changes (in the git repo example, you are creating thousands times the number of repos but each repo is accessed way less often, and in many cases a repo might never be accessed again after 30-60 seconds), you need to compact differently. Your sharding, file layout, metadata management, and storage format strategies may also need to change.
Consider filesystems in agent sandboxes. If you have huge numbers of tiny sandbox filesystems, what is the right implementation? The simple solution is an individual volume per sandbox, but this is extremely expensive. The more complex solution is a shared volume base with per-sandbox copy-on-write overlays - which is what many of the more advanced agent sandbox vendors now do. But this then introduces new questions - what is the set of bases you store? When is it better to have a new base vs. store a diff? How do you re-balance your bases over time as the filesystems evolve? A whole new design space emerges to try to solve the problem.
As another example, the CEO of Firebolt recently put together a good presentation for Iceberg Summit discussing how agent workloads require a substantial rethinking of some combination of the Iceberg storage format and query engines above it.
Beyond being higher volume, agents also tend to be far more iterative than humans, and are often most effective assuming rapid iteration with a tight feedback loop. A human that needs to do a big analysis might meticulously write the query that does the entire thing, all at once. Agents tend to be better at writing a baseline query, looking at the results, repeating at high rate. This lends itself much more towards these sorts of “small data” systems, where a lot of small queries build up on one another.
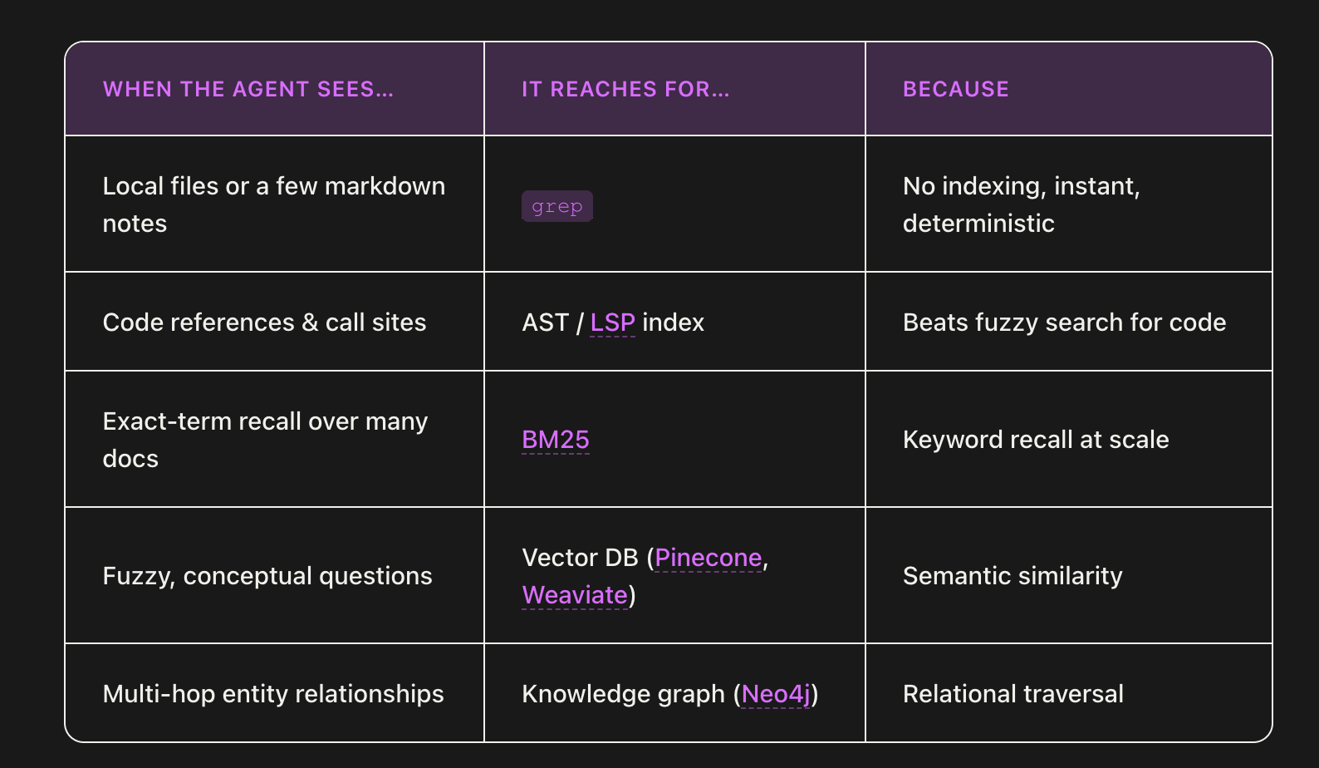
A good example of this is the popularity of grep in coding agents over more complex, high scale search databases - it is easier for the agent to run a massive number of smaller grep queries in many situations.
As a result, systems designed for high volumes of “small data” tend to work better for agents - e.g. SQLite, Motherduck, Bauplan, etc. These systems can not support extremely large scale data workloads and tend to be designed to run only on single machines (vs. distributed), but in return they are simpler to run, lower cost, and more performant within that scale.
High volume, low cost
Agents tend to dramatically increase the overall load on systems for a few, multiplicative reasons.
First, agents tend to be expansionary in terms of how often infrastructure is used - e.g. vibe coding platforms and Claude Code are resulting in many orders of magnitude more code in the world than existed before, data analyst agents are resulting in way more people running way more data analysis queries than before.
Second, as I mentioned earlier, agents’ more parallel approach to querying systems also mean each of those individual tasks tend to involve way more queries to the system.
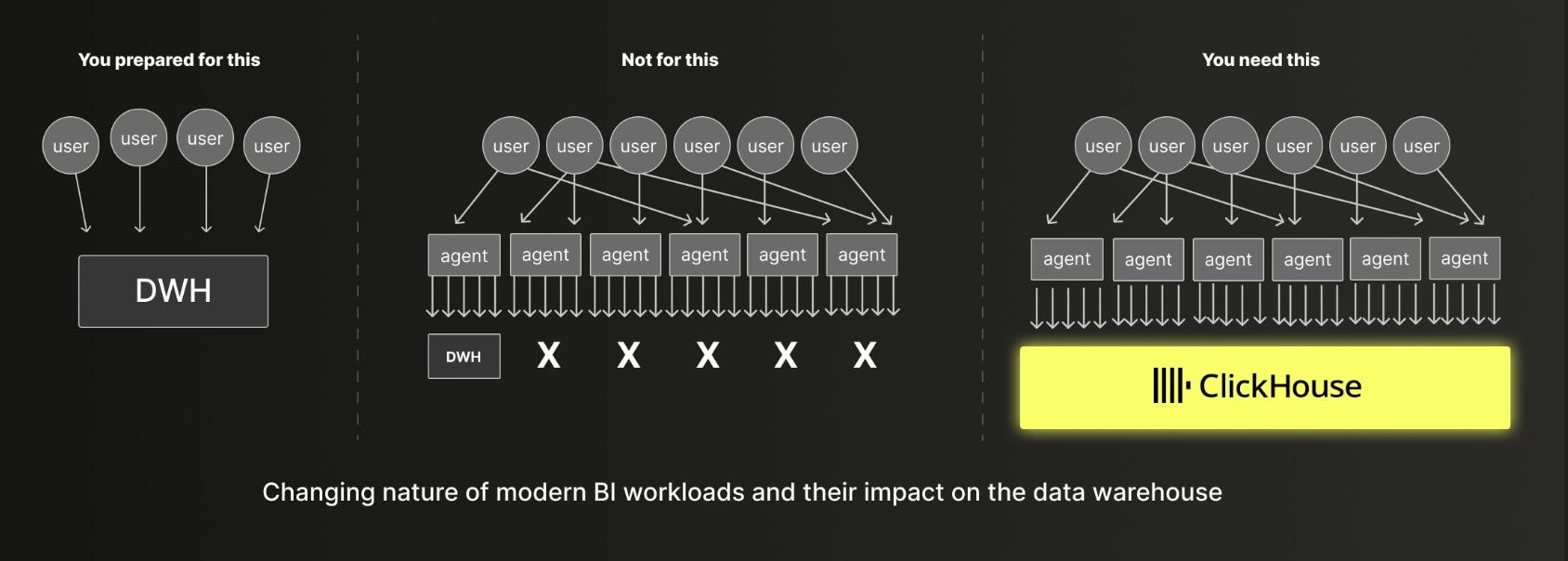
As a result, the effective query load on a system is likely to go up by many orders of magnitude relative to what it was before, which can explode cost. One portfolio company I work with, Bauplan, is seeing data workloads grow by 10-100x once agents use their DB vs. humans. Clickhouse’s visual below captures this explosion of volume well.
This greatly increases the importance of cost reduction mechanisms and architectures that solve for cost - such as tiered storage architectures, sophisticated caching, or compression techniques.
As an example, Turbopuffer’s object storage native architecture gained a lot of traction over earlier in-memory vector DBs like Pinecone thanks to offering an insane cost reduction (100x+). The primary user of vector databases are agents running retrieval queries as a tool to gather context, and complex agents want to run tons of retrieval queries to solve a task. The cost component was a fundamental enabler of the desired agent workload pattern.
To my earlier point about “high volume, small data” - Turbopuffer’s architecture also optimized for a large # of (relatively) smaller vector index namespaces, rather than a small number of very large vector index namespaces which is what was much more common in traditional search use cases like consumer web search or eCommerce recommendation systems. This tradeoff maps very well to vertical RAG & agent companies - e.g. Turbopuffer has to serve Cursor, which has millions of customers each with their own set of search namespaces which are dynamically queried by the Cursor agent.
Session-based, stateful queries
Relative to humans, agents tend to be much more session-oriented in how they engage with systems. Consider web search as an example. A given human looking something up might type a query, look at the results, and may perhaps repeat once or twice but for the most part the search is singular and one-off.
In contrast, agents default to highly, highly sequential queries that all build off of each other. You see this, for example, with how coding agents use grep - it is not uncommon for a coding agent to run 5, 10, or even 30 sequential search queries in a row against your codebase to find what it is looking for, each refined from the last.
From a systems perspective, what makes this pattern interesting is that it is possible to natively bake the idea of a “session” into a query system, not dissimilar from how recommendation systems in products like TikTok have traditionally used the full sequence of actions a user has taken to inform the next suggestion.
Going back to the web search example, most web search APIs today have no concept of stored state across queries - each query is stateless, not informed at all by previous queries. This is because the traditional way web search APIs have been used is extremely one off. Recommendation systems generally only work when there is a lot of sequential interaction data - humans don’t demonstrate this except in consumer product categories like social media, but agents demonstrate it everywhere.
What if instead, the web search API had a session ID that could be used to allow each successive query to be partially informed by previous queries, skewing the search away from results you’ve already seen and towards a more refined understanding of what you want?
I think there is a lot of optimization that could be done in a such a case, such as:
Caching of incremental or partial results likely to re-appear in subsequent queries (see this paper as a similar idea in DBMS)
Intelligent reformulation of query N via a semantic understanding of what the user attempted to do in queries 0...N to avoid repeated or redundant work
Predictive querying of data in anticipation of what an agent is likely to query next
Clickhouse touches on the idea of a stateful session in their recent blogpost on “Agent Facing Analytics”:
A server-side state for AI Memory
AI systems can retain and recall information over time which can help them make better decisions, personalize responses, or improve performance based on past interactions. This is often referred to as “AI memory”.
In the database, we can envision server-side features to support maintaining a state for the agents, the same way interactive users can maintain sessions with their settings and preferences preserved. This can be extended to various cache levels if recurring queries are submitted (especially relevant for data discovery queries) and will require reliable ways to identify agent users and the scope of their tasks.
This idea, by the way, can also be mapped to the parallel query patterns I described early - agents both branch wide and recurse deeply, and really you want the system to understand that all of this maps to a single “session” where the agent is trying to analyze or understand something.
Open the engine
I generally think that the rise of agents manipulating systems will lead many systems to expose a lot more, lower level APIs and “open their engine” more, because agents are FAR more capable of manipulating these low level APIs than humans.
Agents - as a general rule - want thin, dumb APIs, not “thick” APIs. Doug Turnbull’s blog does an excellent job articulating why this is the case for search engines (see also liberating search from the search engine). Most search engines today natively bake in a lot of logic around query understanding, query expansion, ranking, boosting, rescoring, etc. Such engines expose some ability to tweak this, but a lot of it is more like black magic in the engine.
But when LLMs are your user, you have transitioned from a dumb client, smart server assumption to a smart client assumption. The LLM is, in many cases, better at doing some of these things like query expansion and query understanding than your system is! And so the traditional breakdowns of what a system should do on its own vs. what it should let the client influence change, and in many cases you want to allow the client to manipulate all of these things in a much more precise, controlled fashion.
Imagine a web search API that exposed all the ranking systems, all the search metadata, all the query expansion, all the indices, and more to the agent, allowing it to very precisely articulate what it does and doesn’t want to do for each query. I have spoken to multiple senior people at leading AI labs who have begged the major web search API providers for agents to build this as they know it would improve their agent’s quality - but thus far no one has built it. They have clearly seen in internal evals that each incremental degree of control improves the agent’s quality on web retrieval. Instead, we’re left with web search APIs that still treat the entire search engine as a black box, supporting at most a few query parameters on top of your query.
When you are serving humans, exposing too much customization and flexibility can really shoot you in the foot - the system becomes too complex to learn, it is too easy for your users to mess things up, and the benefits your users get from such degree of an open system is often minimal. But, this all changes when you are serving agents - who in many cases are much better at conceptualizing the full scope of the system, and are often better at dynamically tweaking all of these parameters.
This blog post by Shaped is a great illustration of this concept - discussing how “information retrieval is moving from a static pipeline to a dynamic decision tree, where the agent builds and provisions the right tool on the fly based on the data”. They argue the right architecture for that is an information retrieval system that lets an agent dynamically compose arbitrary sets of retrieval systems as it does its work, rather than a more opinionated retrieval system that always does things in a pre-determined or pre-configured way.
The same idea likely applies to many other types of systems - such as query planning and query optimization in SQL databases. We already see agents being potentially more effective at aspects of query optimization than traditional SQL optimizers - such as join order selection (caveating cost/latency considerations). Why shouldn’t agents be able to influence rebalancing, write vs. read amplification, consistency vs. availability, and other common tradeoffs in systems?
I correspondingly think the value of composable, flexible, and “plugin”-able systems will go up a lot. For example, in SQL engines, might Datafusion end up being a more powerful tool than DuckDB for agent usage given Datafusion is so much more modular?
Simulation and sampling
Agents benefit from being able to easily run preliminary tests of ideas in a fast, cheap, non-destructive way before fully doing something. Aside from branching, there are a number of other ways a system might be able to support such workflows.
One is simulation - tooling that makes it easy to mock or mimic what might happen to a production system were a given change to happen. Vera is a cool example of a third party tool trying to do this, though I also think there is an opportunity for production systems to more natively support this kind of workflow.
Second is sampling - a system that can return a preview or directional overview of what will happen if something is done, before it fully occurs.
A simple traditional version of this is how the statistics engines in most SQL query engines can give a likely estimate or bound of the number of rows that will be queried or the estimated cost of a query. These sorts of flows make it easy to give the agent rapid feedback before a high cost or irreversible action is taken.
It’s interesting to consider what it might look like to really design a system around these sorts of probing or exploratory queries such as “SELECT * LIMIT 5” or “SELECT category, COUNT(*) AS C From table GROUP BY 1”. A few things that come to mind include:
Approximate query processing - Exploratory queries are, almost by definition, not very correctness constrained. One could in theory take advantage of this in numerous ways, such as having a long-lived cache for sampling queries you are okay being an hour stale, or allowing the user to provide a correctness bound as a query parameter. Sketches are a popular version of the latter in OLAP databases to efficiently compute an estimate of mean, median, etc, though one could imagine the idea being taken much further - such as allowing a more generalized “precision” parameter on a query.
Specialized storage - Why not have an optimized physical layout on disk for a sample of a table, if it will be one of the most popular types of query an agent runs on that table?
Clickhouse directly touches on this in a recent blog where they discuss how “improved discoverability” is likely one of the key tenets you need to design around when building an OLAP system for agents. They propose building SQL extensions that make this easier - “Think of it like a server-side version of pandas.describe() designed specifically for agents.”
The “Supporting Our AI Overlords” paper outlines a much more ambitious version of optimizing for sampling queries. They discuss designing a database around “probes”, which are semi-structured queries that the system can answer to steer the querying agent. These might include exploratory queries that aim to identify relevant tables or sub-tables (”Which tables relate to sales?”), contextual queries that give background context which allow the system to nudge the agent in the right way (”I am trying to gut check if east coast sales team is doing better than west coast”), or accuracy & termination criteria (”I only need to get a rough sense on whether the east coast team is doing a lot better than the west coast”). The paper explores how one could dramatically redesign a database to support these sorts of inquiries natively, essentially treating this as a first class type of query with its own optimizer alongside traditional SQL queries.
Taking this idea further, you might imagine how a system could be designed to proactively recommend followup queries or related lines of inquiry after an agent makes a query - essentially becoming more like a proactive recommendation system than a passive execution engine.
The broader point is that agents benefit a lot from small nudges, directional answers, and fast feedback - and there are a lot of ways to design a system around this.
Local Execution
Agents particularly benefit from having local, embedded, lightweight versions of systems that they can easily test and iterate on without having to go through the headache of manipulating production infrastructure which has more state, more risk, and more cost associated with it.
As an example, I think that coding agents are massively increasing the need for a way to reliably emulate github actions locally - leading to projects like Agent CI. I would argue grep’s popularity in coding agents is another very good example of this - in many cases it is more efficient for an agent to use the lightweight local search system than the heavy remote search system.
MotherDuck’s original vision of an OLAP data processing system that was built around dual client + server side execution by decomposing a query plan across local storage and cloud storage is interesting idea to potentially revisit. I could see these sorts of hybrid execution architectures becoming more popular in a world of agents where you want the compute speed of the system to be impedance-matched with the reasoning speed of the agent.
Query Complexity
Agents tend to write much more complex queries than humans. Often, they are far more “well-specified”, by that I mean taking advantage of a full set of parameters or operators.
Search is an obvious case of this, where a human search query is often no more than 4-6 words (whether on web, an eCommerce site, or somewhere else), but agents will write much longer search queries mapping to exactly what they are looking for.
This structurally changes how you design a search engine. For example, see how Turbopuffer has updated its search techniques to account for this type of query. Many agents actually try to write web search queries that exceed the query length permitted by most web search engines of 32 words - their system is not structurally designed to fulfill queries longer than that.
In a related vein, I think “operators” - or specialized precise filters in web search engines such as “site:” and “link:” - will need to make a come back for agents. Many web search operators slowly deprecated many operators over the past decade as humans tend not to use them, and they add indexing and query engine complexity on the backend.
This idea applies broadly across query engines and APIs. Because agents are quite capable at understanding documentation and fully taking advantage of very specialized query parameters, the juice may be worth the squeeze to add far more niche query configurations or API parameters if they allow an agent to more precisely define it’s intent and objective.
Other, smaller ideas
Fail fast - As we’ve discussed, agents benefit a lot from fast feedback loops. Another version of this is designing systems to be able to fail much sooner via pre-processing, type checks, and other types of safety checks. This is harder when serving humans because humans tend to be lazy (e.g. see how humans love Python), but agents are very good at annotating code that they write. So, it may be much more tenable to build SDKs and CLIs that have strong typing and other types of validation annotations natively built in
Transactionality - I think agents will favor systems that have strong transactionality guarantees built into to complex sequences of operations. For example, if a data agent needs to ingest data, transform it, and move it somewhere else, the entire loop should be reversible and atomic. It should be impossible to hit a partial execution result. This is a very difficult primitive to build in complex distributed systems, but makes it much more tenable for the agent to try, fail, and iterate.
Putting it together - an observability case study
I’ll round this out with a case study from Firetiger, which recently wrote a great post on designing an observability database for agents.
Observability databases for humans need to primarily optimize for the dashboard use case - low latency queries over very large datasets. A lot of the traditional optimizations in observability serve this use case by attempting to minimize the cost and latency of these large queries, such as by pre-aggregating data, sampling data, caching results, or similar.
As we have discussed, agents, in contrast, want to explore large amounts of data in a much more parallel, exploratory, and dynamic way. The Firetiger team touches on how this greatly increases the importance of:
Supporting exhaustive, high cardinality data - as agents have semi infinite processing bandwidth, can sift through everything, and don’t just want the top level aggregates
Supporting immense query volume due to parallel explorations - increasing the importance of separating compute from storage, having serverless compute workers that can spin up and down quickly, and having strong isolation between workers so they can not block or compete with each other. Basically, you want to optimize for throughput and concurrency, not latency
Dealing with the small files problem for fresh, quickly accessible data - via techniques like an ingest service that merges concurrent writes into tables, and intelligently compacting and expiring older data & metadata
Data discoverability & sampling - Tools for agents to discover what data exists and how to query it
Schematization - To make it easier for agents to understand how to navigate what is normally unstructured telemetry data and increase token efficiency
Note how many of these are hard system tradeoffs - optimizing for aggregates vs. random specialized reads, optimizing for latency vs throughput, optimizing for concurrency vs. serialized operations. These are not minor differences or abstraction sugarcoating.
I thus think it is invariable you will see a new version of every type of computer science system emerge that is designed for agents. The sheer number of ways you can redesign each system is too substantial for this to not be the case.
More fundamentally, I suspect that agents will end up blurring the lines of traditional systems categories, creating new categories all together. One obvious example of this is that agents seem to blur the lines between OLTP and OLAP significantly, which is partially why Databricks is pushing the “lakebase” architecture so much (see also this Clickhouse talk from last year). But, I think this will play out in more complex ways that are difficult to predict right now.
Infrastructure companies deeply exploring these ideas
I am sure there are some I am missing, and of course some of these ideas were popularized in systems completely outside of the scope of AI agents but become more important when serving agents, but nonetheless here is a rough take on the startups more aggressively pursuing the types of ideas outlined in this blog post, separated by category:
CI - Blacksmith, AgentCI
Object Storage - Tigris
OLAP - Bauplan, Motherduck, Clickhouse, Firebolt
Search & Recommendations - Turbopuffer, Chroma, Shaped, Lance, Hornet
General Sandbox/Compute - Modal, Daytona, e2b, Sprites, OpenComputer
I am extremely interested in investing in startups using ideas like these to rebuild or rethink infrastructure categories, and in talking to people redesigning large existing systems along these lines. Please get in touch if so - davis @ innovationendeavors.com
Thanks to Chris Riccomini, Jacopo Tagliabue, Apurva Mehta, & Vedran Jukic for providing feedback & input on this.