
Documentation as tool for agents

I was recently vibe coding a wedding website with Replit, and noticed that Replit Agent now includes a documentation step as part of its workflow. After it finishes a task and thinks it is at a checkpoint, it will autonomously decide to update the documentation in the repository. This was not something I asked it to do.
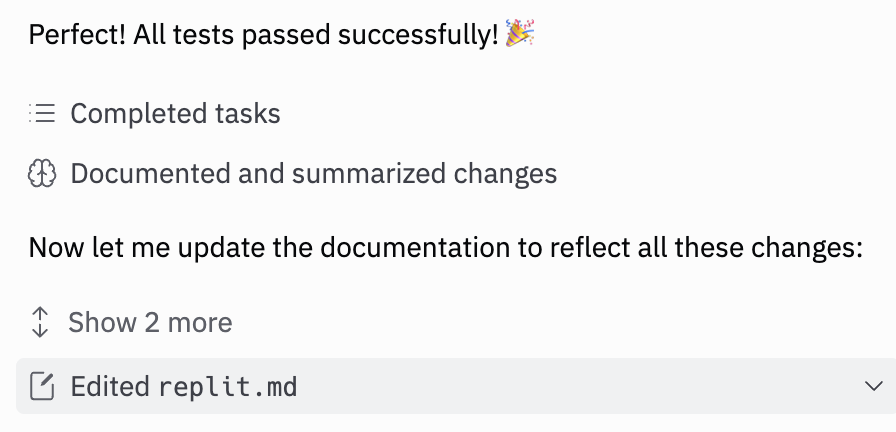
If we look at the Replit.md it produces, we see a README style document that touches on overall intent, design goals, key features, architectural design, and similar.

This is very interesting because, from the perspective of the user, the Replit.md file is mostly an implementation detail. While Replit does allow you to find the file in its file viewer UI, this is fairly difficult to get to, and in the course of “vibe coding” it is not something you are particularly meant to look at.
So, why does Replit do this? My suspicion is that documentation is a tool that improves agent quality. I think this is an under appreciated concept, and one that will become much more prominent over the coming years.
Documentation as an index structure
One lens to think about documentation in the context of coding agents is as an index structure.
Coding agents today use a variety of tools to retrieve and manage context about the codebase - including navigating the abstract syntax tree, lexical & semantic search indices, and search utilities like grep.
Documentation fulfills a similar purpose for coding agents:
It acts as a guide that instructs the agent about what parts of the codebase relate to what functionality, helping the agent know where to look
It elucidates the design intent of code, often sharing details about why something was done, what alternatives were considered, and what was not done. These details are useful, but rarely in the code themselves.
It acts as a materialized cache for reasoning - conveying higher order facts/concepts/principles that could be gleaned from the code, but which would require reading & reasoning over large sections of the codebase
Correspondingly, one might expect that there is a lot of value in having a system attempt to autonomously create, maintain, and update documentation for the agent - not as an artifact for humans, but as an implementation detail that improves agent reasoning.
Yet, this is not really done in the coding agent space at all today. While most mainstream coding agents can of course be used to produce documentation - e.g. you can ask Cursor or Claude Code to produce documents for X or Y - none of them autonomously create a lot of documentation as part of their operations to be used as a data structure in future runs.
Agents.md, which Replit.md is likely a riff on, is the closest to what I am describing, but I think it still leaves a lot to be desired.
The first challenge is that Agents.md is really something that a software engineer is meant to maintain. Anthropic has entire guides dedicated to setting up and managing your Agents.md, and Claude Code expresses the # command for the user to update Agents.md. In some sense - Agents.md is in between a fancy system prompt for Claude Code and an index structure that the coding agent system maintains.
The second challenge is that Agents.md is a relatively simple/naive implementation - it’s a single file that is supposed to globally describe everything in the codebase. You can find various guides online about how to nest hierarchical Agents.md files to try to fix this, but ultimately the onus is on the user to figure out and manage the right Agents.MD structure for their codebases.
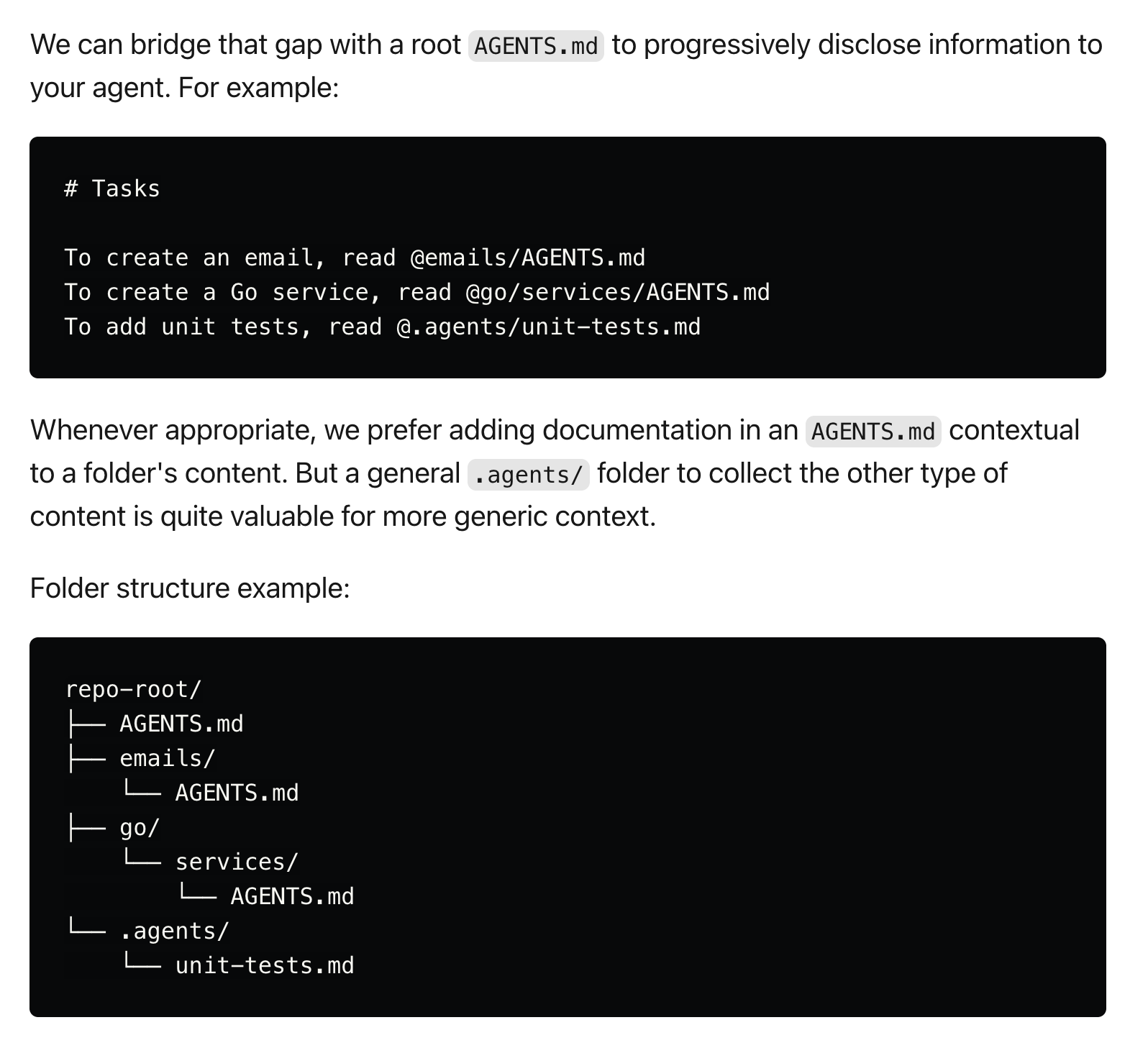
Play this out a bit more, and what you end up with is essentially a human manually having to tune a new type of complex search index structure for their coding agents.
My argument is that we likely need to move to a world where this type of documentation is more autonomously constructed, managed, and updated by the coding agent itself. In other words, documentation becomes a *tool* that the agent can use as part of its operation, just like how the Replit agent decided to write down some documentation updates after I gave it a task.
Such an approach would allow for much richer optimizations of how documentation is structured & laid out, ultimately resulting in far improved coding agent quality.
Blending Human and AI-oriented documentation
I think this is also the right recipe/strategy for starting to blend human-oriented documentation and agent-oriented documentation. It is actually interesting to consider why Agents.md has emerged as this sort of divergent documentation corpus separate from the documentation many engineering teams are already writing.
Indeed, the same guide I listed above that discussed how to create a nested Agents.md structure essentially implicitly recommends against referencing external documentation.
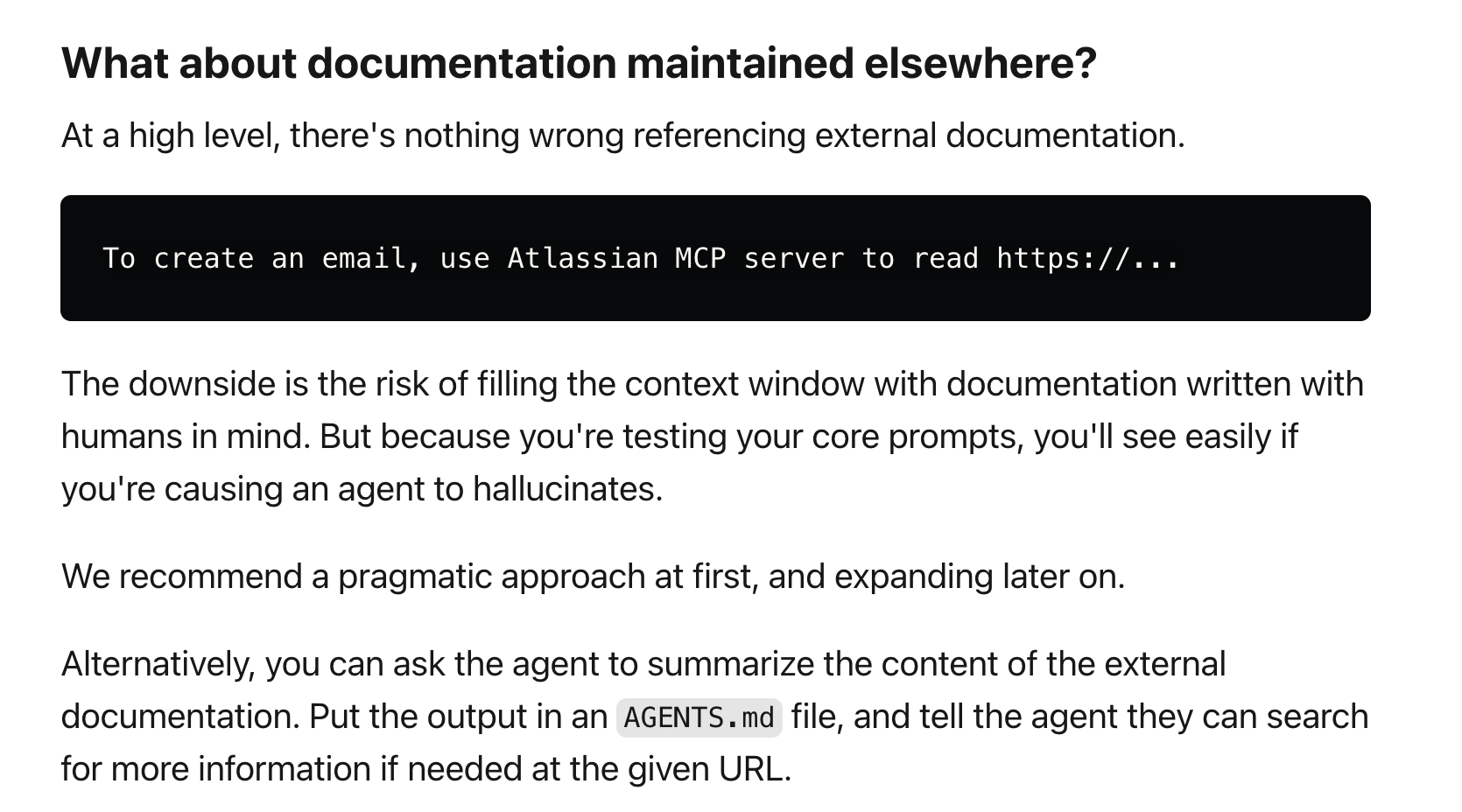
There are certainly well-founded reasons for this - context rot is a real concern, human documentation is likely more verbose and less information dense (worse for agents), and most critically a lot of human documentation is very stale or out of date.
Yet, these are solvable concerns. A proper documentation tool would be able to optimize the right file structure, information hierarchy, and documentation updates to ensure that both humans and AI have effective, useful documentation. You can imagine a world where every codebase has the following:
Human-controlled Agents.md file(s) that allow a human to provide simple preferences or rules it wants the AI to followup - mirroring what tools like Claude Code offer today
A complex hierarchy of “index structure” esque documentation that is primarily managed and maintained by a documentation tool the agent has access to, and viewed as an implementation detail for how to make coding agents more effective
A set of human-oriented documentation that is produced as a sort of materialized view on top of the code + the index structure documentation
My guess is that building an effective agentic system for creating, updating, and managing documentation is a sufficiently rich technical problem that it warrants specialized startups going after it, just like we see with things like memory or semantic search indices.
My intuition is also that this idea extends far beyond just coding agents. Any vertical agent that must regularly reason over a large corpus of data could likely benefit from this concept - e.g. companies like Trunk Tools in construction, Harvey in law, Sierra in customer support.
This resonates! I'm building automated reverse documentation workflows in my repos - every git checkin triggers a documentation update to spec files (some of which are quite granular)
I use the granular docs as context to "@" claude or codex.
Using this while building Socratify
I think you're absolutely right about agents using docs as a great way to store and refresh context, and to get bonus points from their human counterparts. I was quite surprised the first time I used Claude Code and it built robust docs right out of the box without ever being asked, and continued to maintain them. Unfortunately they did drift over time and I did have to tell it to refresh a few times.